GIT
GIT jest obok SVN jednym z najbardziej popularnych systemów zarządzania wersjami kodu źródłowego. Jest on wykorzystywany w wielu otwartych projektach, między innymi jądro systemu Linux jest trzymane w Gicie.
Dokumentacja
- Git Book – elektroniczna książka o Gicie
- Git cheatsheet – podstawowe komendy w zwięzłej formie
- Git tutorial – przyjazny przewodnik po gicie
- Interaktywny, wizualny przewodnik po komendach Gita
Prerekwizyty
- migawka VirtualBoksa z zainstalowanym systemem operacyjnym
- przeczytanie rozdziałów 1,2 i 3 z książki Git Book
- znajomość pojęć: system zarządzania kodem źródłowym, VCS, DVCS, repozytorium kodu źródłowego, kopia robocza, indeks, gałąź, commit, repozytorium centralne/główne, repozotorium gołe (bare), klonowanie repozytorium, poczekalnia, zdalne repozytorium, merge, konflikt, gałąź
master, repozytoriumorigin
Zadania do wykonania
- zalogowanie się na maszynę wirtualną w oknie terminala maszyny fizycznej
- zainstalowanie gita (na maszynie wirtualnej – pakiet dev-vcs/git)
- skonfigurowanie gita tak by domyślnie wyświetlał pokolorowane wyniki oraz zawierał dane identyfikujące studenta/studentki:
- imię i nazwisko oraz e-mail: imie.nazwisko@virtual.com – na maszynie wirtualnej
- imię i nazwisko oraz e-mail: imie.nazwisko@host.com – na maszynie hosta
- utworzenie katalogu /home/<login>/project<nr_grupy> na maszynie wirtualnej
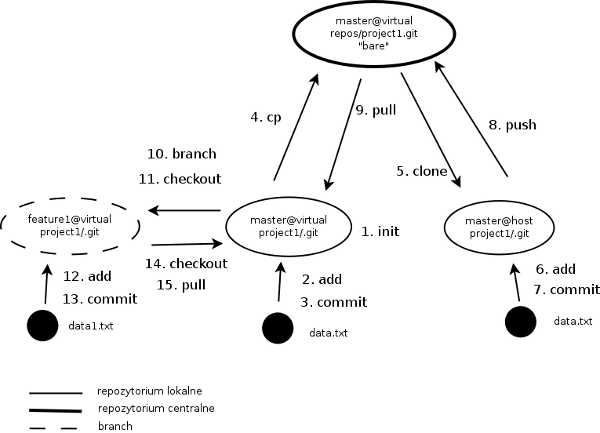
- (1) zainicjowanie repozytorium git w katalogu project<nr_grupy>
- utworzenie pliku data.txt w katalogu projekt, zawierającego imię i nazwisko studenta/studentki
- (2,3) dodanie pliku data.txt do repozytorium lokalnego
- utworzenie katalogu /home/<login>/repos na maszynie wirtualnej
- (4) sklonowanie repozytorium lokalnego project<nr_grupy>/.git do katalogu /home/<login>/repos/project<nr_grupy>.git z opcjami “bare” i “shared” (rozdział czwarty) – utowrzone repozytorium będzie pełnioło rolę repozytorium “centralnego” (na rysunku oznaczone jest jako “bare”)
- (5) sklonowanie repozytorium “centralnego” na maszynę hosta (ssh://<login>@adres.ip.maszyny.wirtualnej:22/home/<login>/repos/project<nr_grupy>.git)
- (6) dodanie na maszynie hosta wpisu w pliku data.txt zawierającego numer IP hosta
- (7) zatwierdzenie zmian w repozytorium hosta
- (8) przeniesienie zmian z repozytorium hosta do repozytorium “centralnego”
- (9) pobranie zmian do lokalnego repozytorium maszyny wirtualnej
- (10,11) utworzenie nowej gałęzi (brancha) o nazwie “feature1” na maszynie wirtualnej
- utworzenie pliku data1.txt zawierającego adres e-mail studenta/studentki
- (12,13) dodanie pliku data1.txt do gałęzi “feature1”
- (14,15) pobranie zmian z gałęzi “feature1” do gałęzi głównej (“master”)
Warunki powodzenia
- wyświetlenie logu zmian repozytorium na maszynie wirtualnej zawierającego wszystkie operacje na plikach data.txt i data1.txt zgodnie z powyższym opisem
Schemat ćwiczenia
GIT – podstawy
Materiał opracował Wojtek Zając
Koncepcja repozytoriów kodu źródłowego
Repozytoria kodu źródłowego służą do usprawnienia pracy nad kodem, szczególnie w kilka osób. Pozwalają na lepsze śledzenie zmian oraz ułatwiają rozwiązywanie problemów (konfliktów), które pojawiają się kiedy dwie osoby modyfikują ten sam plik. Serwer z repozytorium przechowuje kompletną historię zmian, przez co możemy łatwo cofnąć się do wcześniejszej wersji kodu. Zmiany możemy wysyłać grupowo, po zmodyfikowaniu większej ilości plików. Repozytoria dają możliwość prowadzenia kilku gałęzi kodu, które mogą być rozwijane niezależnie. Kolejną przydatną funkcjonalnością są tagi, które pozwalają oznaczać wersje kodu, np. oznaczenie konkretnej wersji wydawanego produktu lub biblioteki.
Rozproszone repozytoria kodu źródłowego
W rozproszonych repozytoriach kodu źródłowego klienci nie dostają dostępu tylko do najnowszej wersji danych, ale kopiują całe repozytorium wraz z jego historią. W wypadku, gdy jedno z repozytoriów ulegnie awarii, całość może być odzyskana z jego kopii na dowolnym serwerze. Każde repozytorium rozproszone ma stowarzyszoną z nim kopię lokalną. Dodatkowo, żadne z repozytoriów nie jest wyróżnione ‘fizycznie’, chociaż może być ono wyróżnione logicznie (np. poprzez oznaczenie w liście repozytoriów).
Omówienie pojęć
- Kopia robocza: kod źródłowy, do którego aktualnie mamy dostęp.
- Indeks: lista różnic pomiędzy daną kopią roboczą, a istniejącym repozytorium, które zostały wybrany, aby zostać zatwierdzone w następnej zmianie. W jego skład wchodzą tylko pliki, które są śledzone.
- Repozytorium: miejsce, w którym przetrzymywany jest kod źródłowy z możliwością jego aktualizacji i pobierania (może być lokalne lub zdalne)
- Poczekalnia: modyfikacje plików oraz nowe pliki, które nie zostały dodane do indeksu.
Podstawowa praca z Gitem
Konfiguracja
Jeśli po raz pierwszy chcemy skorzystać z GITa na naszym komputerze, musimy ustawić dane, które pozwolą na identyfikację wprowadzanych przez nas zmian.
$ git config --global user.name "Imię Nazwisko" $ git config --global user.email "xxx@gmail.com"
Uwaga: $ reprezentuje znak zachęty – aby wykonać polecenie nie wprowadzamy go w linii poleceń.
Będąc w katalogu w którym chcemy mieć projekt, mamy do wyboru dwa wyjścia.
Inicjacja nowego repozytorium
$ git init
Klonowanie
Alternatywnie, możemy sklonować istniejący projekt na swój komputer.
$ git clone https://github.com/jquery/jquery.git
Dodawanie plików, wprowadzanie zmian
Po zakończeniu pracy sprawdzamy które pliki zostały zmodyfikowany.
$ git status
Następuje wyraźny podział na pliki w indeksie (ang. staging), oraz poza nim (poczekalnia). Gdy chcemy dodać pliki z poczekalni (ang. unstaged) do indeksu, wpisujemy polecenie:
git add plik1 plik2 plik3
Alternatywnie, możemy dodać wszystkie pliki w katalogu.
$ git add .
Commitowanie
Commit to dodanie zmian z indeksu do repozytorium.
$ git commit -m "Wiadomość"
Wieloosobowy dostęp do repozytorium
Git, jak inne systemy kontroli wersji, zawiera mechanizmy mergowania (łączenia) plików. To oznacza, że nad jednym plikiem wspólnie może pracować kilka osób, ponieważ zmiany w późniejszym czasie mogą być ze sobą połączone.
Rozwiązywanie konfliktów
W wypadku, gdy automatyczne połączenie plików nie jest możliwe, powstaje konflikt. Plik w konflikcie ma oznaczenie unmerged (widnieje po wykonaniu polecenia git status).
Wszystko, co musimy zrobić to usunięcie skonfliktowanego fragmentu z pliku, ponowne dodanie go do poczekalni i wywołanie git commit.
Zdalne repozytoria
Sprawdzamy listę zdalnych repozytoriów za pomocą polecenia
$ git remote -v
Jeśli nasze repozytorium zostało sklonowane z serwera, pojawi się URL obok nazwy repozytorium origin.
Dodawanie zdalnego repozytorium
Możemy dodać nowe repozytorium za pomocą polecenia
$ git remote add zdalne git://github.com/test/zdalne.git
Wysyłanie zmian do innego repozytorium
Podane polecenie prześle zmiany z naszej podstawowej gałęzi lokalnej (master) na domyślny zdalny serwer (origin).
$ git push origin master
Pobieranie zmian z innego repozytorium
Aby uzyskać zmiany ze zdalnego repozytorium korzystamy z:
$ git fetch zdalne
Możemy również skorzystać z polecenia pull, które alternatywnie złączy zmiany z serwera z kopią roboczą nad którą aktualnie pracujemy, np.
$ git pull origin master
Gałęzie kodu (branch)
Gałęzie kodu służą do prowadzenia osobnych wątków projektu, które na końcu możemy łączyć (powrócić do głównego wątku). Pozwalają np. na rozwój eksperymentalnych części projektu, które mogą lecz nie muszą być wprowadzone do finalnego produktu.
Tworzenie gałęzi
Domyślną gałęzią jest master. Aby stworzyć gałąż testowa, wykonujemy następujące polecenia:
$ git branch testowa $ git checkout testowa
W tym momencie dokonywane zmiany pojawią się tylko na gałęzi testowa.
Łączenie gałęzi
Kiedy stwierdzimy, że gałąź testowa nadaje się do połączenia z głównym wątkiem projektu, możemy je połączyć.
$ git checkout master $ git merge testowa
Oraz usunąć nieużywaną gałąź.
$ git branch -d testowa
Przydatne polecenia
commit --ammend
W wypadku, gdy zapomnieliśmy dodać pliku do wysłanego commita, możemy wciąż go dodać za pomocą flagi ammend.
$ git commit -m 'Commit który powinien być kompletny' $ git add zapomniany_plik $ git commit --ammend
git stash
Polecenie stash pozwala na chwilowe “odsunięcie” aktualnie wprowadzonych do projektu zmian bez konieczności commitowania ich. Można następnie dodać inne zmiany i powrócić do poprzedniej pracy. To polecenie działa podobnie do schowka w systemie operacyjnym – zmiany możemy “wyciąć” a następnie w “wkleić” tam gdzie będzie to potrzebne. Jednak w przeciwieństwie do schowka, tego rodzaju wyciętych fragmentów możemy dowolna ilość.
git cherry-pick
Polecenie cherry-pick pozwala na przenoszenie poprawek kodu na podstawie ich sumy pomiędzy poszczególnymi gałęziami.
git add --patch
Flaga patch pozwala na interaktywne wprowadzanie zmian do indeksu – pozwala to np. na dodanie tylko niektórych zmian wprowadzonych w obrębie jednego pliku. na maszynę hosta (ssh://student@adres.ip.maszyny.wirtualnej:22/home/student/repos/project